Benutzerdefinierte Dateisignaturregeln
Dies richtet sich hauptsächlich an Ingenieure und Datenrettungsexperten, obwohl jeder Enthusiast es problemlos aufgreifen und ausprobieren kann!
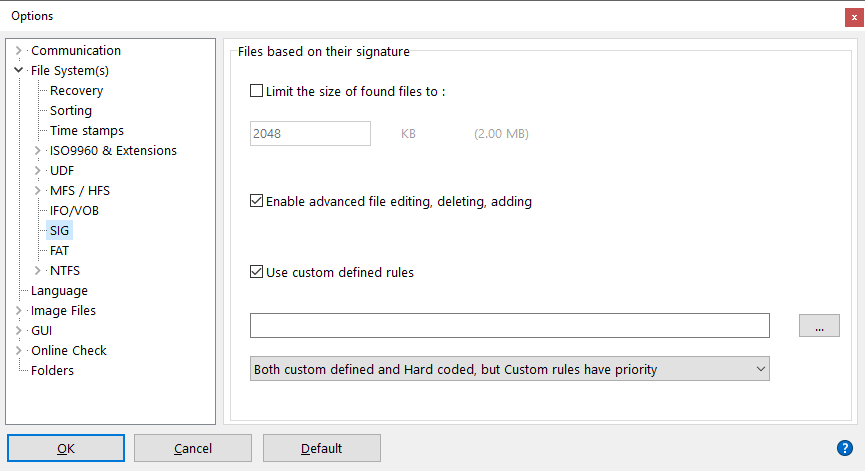
IsoBuster kann benutzerdefinierte Regeln laden und verwenden, um Dateien anhand der definierten Signatur zu finden.
*.rules-Dateien sind reine Textdateien, die eine Regel pro Zeile enthalten und an beliebigen Orten gespeichert werden können, von denen aus sie geladen werden können. Oder legen Sie sie einfach in den /plugins/-Ordner.
Sie können die *.rules-Datei, die IsoBuster verwenden soll, über die Optionen auswählen. Siehe Screenshot oben.
Wenn das Kontrollkästchen "Benutzerdefinierte Regeln verwenden" aktiviert ist, lädt und verwendet IsoBuster die definierte *.rules-Datei bei jedem "Fehlende Dateien und Ordner finden", um die Liste "Dateien basierend auf ihrer Signatur gefunden" im Dateisystem zu füllen.
Es gibt drei mögliche Szenarien für die Verwendung benutzerdefinierter Regeln. Diese können über das Dropdown-Menü unten im Fenster ausgewählt werden (siehe Screenshot oben):
- Nur die benutzerdefinierten Regeln.
- Sowohl die fest codierten (im Programm eingebetteten) Regeln als auch die benutzerdefinierten Regeln, aber zuerst werden die benutzerdefinierten Regeln geprüft, und wenn keine Übereinstimmung gefunden wird, werden die fest codierten Regeln verwendet.
- Sowohl die fest codierten (im Programm eingebetteten) Regeln als auch die benutzerdefinierten Regeln, aber zuerst werden die fest codierten Regeln verwendet, und wenn keine Übereinstimmung gefunden wird, werden die benutzerdefinierten Regeln getestet.
*.rules-Dateien enthalten eine Regel pro Zeile.
Da das Parsen einer Textdatei nicht so schnell ist wie eingebetteter Code, ist die Syntax jeder Zeile sehr strikt! Sobald die Syntax nicht den unten aufgeführten Regeln folgt, schlägt der Test entweder fehl oder kann möglicherweise ein falsch positives Ergebnis auslösen.
Es ist am besten, nur gültige Regeln in eine *.rules-Datei zu schreiben und Kommentare etc. außerhalb der Datei zu halten, möglicherweise in einer zweiten Datei, da dies die Geschwindigkeit verbessert.
Um eine Regel zu testen, kann es hilfreich sein, die Zieltyp-Datei in IsoBuster zu laden (als vermutete Image-Datei) und "Fehlende Dateien und Ordner finden" auszuführen. Wenn die definierte Signatur bei Adresse (LBA) 0 gefunden wird, funktioniert die Regel.
Jede Regel wird gegen jeden gelesenen Block getestet.
Für jeden Block wird also die gesamte Liste aller Regeln geprüft, bevor zum nächsten Block übergegangen wird.
Wenn das Medium optisch ist (CD, DVD, BD), wird die Regel auf jeden 2048-Byte-Block angewendet. Wenn es sich um eine Festplatte oder einen USB-Stick handelt, wird die Regel auf jeden 512-Byte-Block oder auf 4096-Byte-Blöcke bei 4kn-Laufwerken angewendet.
Der Startoffset ist in jedem Block 0, es sei denn, IsoBuster erkennt eine Dateisystemstruktur, die einer möglichen Datei innerhalb desselben Blocks vorausgeht, z. B. Dateien, die in NTFS- oder FAT-Dateideskriptoren eingebettet sind.
Blöcke mit bestimmten Dateisystemstrukturen, die keine Datei enthalten, werden übersprungen und nicht weiter getestet.
Jeder Block wird gegen jede Regel in der Regeldatei getestet, bis eine Zeile mit den Daten übereinstimmt; danach wird der nächste Block getestet.
Jede Regel arbeitet byteweise, beginnt bei Index 0 des präsentierten Blocks und geht zum nächsten Byte über, sobald ein Byte gegen den Wert in der Regel getestet wurde.
Jeder Befehl in der Zeile wird mit einem Backslash escaped und ist nur ein Zeichen groß. Backslash und Befehl zusammen sind also immer 2 Zeichen.
Die Werte und Befehle in einer Regel/Zeile:
\%
Ein Kommentar [Funktion verfügbar seit IsoBuster 4.7]
Alles, was nach diesem Befehl in einer Zeile steht, wird ignoriert. Alles davor wird normal verarbeitet. Fügen Sie also keine führenden Leerzeichen hinzu, da diese nur die Verarbeitung während des Scans verlangsamen.
\i()
Weist einer Zeile eine eindeutige ID zu [Funktion verfügbar seit IsoBuster 4.7]
Dies ermöglicht anderen ID-bewussten Befehlen, ihre Funktion auf diese bestimmte Zeile bzw. auf die Datei anzuwenden, die durch diese Zeile gefunden wurde.
Eine ID kann nicht 0 (Null) sein und muss kleiner oder gleich 65535 (0xFFFF) sein.
\e()
Beendet eine zuvor gefundene Datei (die noch geöffnet ist) [Funktion verfügbar seit IsoBuster 4.7]
Dieser Befehl ist ID-bewusst (ID zwischen den Klammern angeben)
Wenn eine Datei über ihre Signatur gefunden wurde, aber noch keine neue Signatur erkannt wurde und die Dateigröße noch wächst, kann dieser Befehl verwendet werden, um die Datei zu beenden.
Idealerweise wird er mit einer ID ausgegeben, die einer anderen Zeile entspricht (und somit dem Dateityp).
Wird kein Wert/ID zwischen den Klammern angegeben, beendet dieser Befehl jede noch wachsende gefundene Datei.
Im letzteren Szenario wird er verwendet, um Signaturen zu erkennen, die jede Datei beenden, aber nicht selbst Teil einer Datei sind.
\c()
An eine zuvor gefundene Datei anhängen (die noch geöffnet ist) [Funktion verfügbar seit IsoBuster 4.7]
Dieser Befehl ist ID-bewusst (ID zwischen den Klammern angeben)
Wenn die Signatur in dieser Zeile mit den Daten übereinstimmt, wird die zuvor gefundene Datei nicht beendet und eine neue gestartet, sondern die zuvor gefundene Datei wächst weiter.
Die Daten werden somit an die zuvor gefundene Datei angehängt. Dies mag wie ein unnötiger Befehl erscheinen, ist jedoch besonders nützlich für wiederkehrende Signaturen in Dateien.
Anstatt jedes Mal x Dateien zu finden, wenn die Signatur erkannt wird, hilft dies, eine Datei zu finden, die die x Signaturen enthält.
Beispielsweise stellt die Zeile \i(1)\c(1)\x00\x00\x01\xba\|.VOBsicher, dass nicht x VOB-Dateien mit 2048 Bytes gefunden werden, sondern stattdessen eine Datei mit x * 2048 Bytes.
\#
Die Größe einer Datei zu ermitteln ist Schätzarbeit. Im Allgemeinen wird die Größe einer Datei durch den Startort der nächsten Datei oder durch eine gefundene Dateisystemstruktur bestimmt.
Trifft IsoBuster auf eine Dateisystemstruktur und geht davon aus, dass die zuvor gefundene Datei hier endet, wird ein boolescher Parameter an den nächsten Test/Block übergeben.
Dieser boolesche Parameter kann verwendet werden, um nurauszulösen, wenn der Wert wahr ist. Befehl \#macht genau das.
Zum Beispiel, Sie wissen, dass eine Datei mit zwei Bytewerten \x1F\x8B beginnt.
Diese Signatur ist jedoch so generisch, dass sie oft innerhalb vorhandener Dateien gefunden wird, was viele falsch-positive Ergebnisse verursacht und zuvor gefundene Dateien verkürzt.
Eine solche Regel sollte am besten weggelassen werden, kann aber dennoch erlaubt werden, nurwenn IsoBuster signalisiert, dass die zuvor gefundene Datei ohnehin bereits beendet wurde.
In diesem Fall könnten Sie die Regel \#\x1F\x8B\|.gzverwenden.
Setzen Sie \# als ersten Befehl in einer Zeile, wenn Sie ihn verwenden. Dies verbessert die Geschwindigkeit erheblich.
\|
Aus Geschwindigkeitsgründen beginnt jede Zeile mit dem Test und endet mit dem Befehl \|
\|wird von der Erweiterung gefolgt, z. B.: \#\x1F\x8B\|.gz
Optional kann die Erweiterung durch |Dateigröße in Bytes ergänzt werden. Dies kann verwendet werden, wenn Sie wissen, wie groß die Datei tatsächlich ist. Beispiel: \#\x01\x02\|.gz|1000
\x
Jeder Byte-Test in der Regel kann auf zwei Arten angegeben werden: als Hexadezimalwert \x00oder als ASCII-Wert (siehe weiter unten).
Die Syntax ist sehr strikt. Es mussimmer zwei Zeichen in der hexadezimalen Notation haben und der Bereich ist \x00 - \xFF.
Es ist auch möglich, nur ein Nibble zu testen. In diesem Fall verwenden Sie ?für das Nibble, das Sie nicht testen möchten. Z. B. \0x?3stimmt mit den Bytewerten 0xF3, 0xE3, 0xD3, ..., 0x23, 0x13, 0x03 überein.
\x??bedeutet, dass dieses Byte überhaupt nicht getestet werden soll, es kann jeden Wert haben, wie das Überspringen eines Bytes. Beispiel: In der Sequenz \0x00\0x01\x??\x01\x00 müssen die Bytes 0,1,3 und 4 übereinstimmen, Byte 2 kann jeden Wert haben.
PS: Verwenden Sie das Nibble-Wildcard ?nicht in Bytewerten, die kleiner oder größer (oder gleich) sein müssen. Also nicht in Kombination mit \> oder \< oder \>= oder \<=, da dies undefinierte Effekte hätte und daher unzuverlässig wäre.
ASCII-Zeichen
Alle lesbaren Zeichen zwischen Bytewert 32 und 126 können verwendet werden, um zu testen.
Zum Beispiel: GIF\|.gifist ein gültiger Test und entspricht im Wesentlichen: \x47IF\|.gifoder G\x49F\|.gifetc.
\ ist ebenfalls ein gültiges Zeichen, muss aber verdoppelt werden, wenn Sie es als Testwert verwenden, da der Backslash zur Maskierung spezieller Werte und Befehle dient: \\
\v()
Vergleiche den Bytewert am aktuellen Offset mit einem Bytewert am Offset, der mit \v() definiert ist.
Der Wert in den runden Klammern ist entweder dezimal oder hexadezimal. Letzteres erfordert die Notation 0x, z. B. \v(0x0F) prüft, ob der aktuell getestete Bytewert mit dem Bytewert am Offset 15 übereinstimmt. Dieser Befehl kann mit \> \< \<= und \>= kombiniert werden.
Zum Beispiel prüft dieses Beispiel: \v(5)\x10, ob das erste Byte am Offset 0 mit dem Byte am Offset 5 übereinstimmt und, falls ja, ob das zweite Byte am Offset 1 mit 0x10 übereinstimmt.
\p()
Ändert die absolute Position / den Offset im Datenblock, bevor der nächste Test durchgeführt wird.
Zum Beispiel: \p(3)\x01\x02bedeutet, dass der Offset von 0 auf 3 geändert wird, und daher Byte 3 im Datenblock mit 0x01 und Byte 4 mit 0x02 übereinstimmen muss.
Sie können zu jeder Position im Datenblock springen, müssen jedoch innerhalb der Blockgrenzen bleiben, sonst schlägt der Test fehl.
Sie können vor- und zurückspringen, wenn dies aus welchem Grund auch immer sinnvoll ist. Zum Beispiel, um aus Geschwindigkeitsgründen einen sehr strikten Bytewert weiter im Block zu testen und nur wenn dieser passt, zurück zum Anfang des Blocks zu springen und andere Bytes zu testen.
Zum Beispiel: \p(100)PP\p(0)\f(100,OK)prüft auf das Vorhandensein von "P" am Offset 100 und "P" am Offset 101, und wenn dies zutrifft, durchsucht es die ersten 100 Bytes nach dem Text "OK".
Der Wert in den runden Klammern ist entweder dezimal oder hexadezimal. Letzteres erfordert die Notation 0x, z. B. \p(0xFF) springt zu Offset 255 usw.
\s()
Ändert die Position, indem eine Anzahl von Bytes vom aktuellen Offset übersprungenwird.
Beispiel aus vorher: \0x00\0x01\x??\x01\x00 könnte auch geschrieben werden als: \0x00\0x01\s(1)\x01\x00
Der Wert in den runden Klammern ist entweder dezimal oder hexadezimal. Letzteres erfordert die Notation 0x, z. B. \s(0x10) überspringt 16 Bytes.
Es ist auch möglich, eine negative Anzahl Bytes zu überspringen (nur mit Dezimalnotation).
Zum Beispiel \s(-1) springt ein Byte zurück. Dies ist nützlich, um einen einzelnen Bytewert gegen mehrere Parameter zu testen, z. B. wenn ein Bytewert zwischen zwei Werten liegt.
Beispiel: \>\x10\s(-1)\<\=\x20prüft, ob ein Bytewert größer als 16 und kleiner oder gleich 32 ist.
\=
= wird implizit angenommen und ist redundant.
Jeder Byte-Test geht davon aus, dass das Byte im Datenblock mit dem Byte in der Regel übereinstimmt.
Wenn jedoch hinter \>oder \<gesetzt wird, z. B. \>\= oder \<\=, wird dies zu >= oder <= übersetzt.
\>
Setze \> vor einen Bytewert, z. B. \>\x33bedeutet, dass das Byte im Datenblock größer als 0x33 sein muss (anstatt gleich 0x33 zu sein).
Wird sofort von \= gefolgt, bedeutet es >=, z. B. \>\=\x33bedeutet, dass das Byte im Datenblock größer oder gleich 0x33 sein muss.
\<
Setze \< vor einen Bytewert, z. B. \<\x50bedeutet, dass das Byte im Datenblock kleiner als 0x50 sein muss (anstatt gleich 0x50 zu sein).
Wird sofort von \= gefolgt, bedeutet es <=.
\f()
Sucht eine Bedingung ab dem Startoffset über einen definierten Bereich. Wird die Bedingung erfüllt, befindet sich der nächste Offset direkt nach der gefundenen Bedingung.
Die Syntax muss\f(range,condition) sein.
Halten Sie den Bereich innerhalb des Blocks. Die Bedingung kann alles sein, was mit den hier beschriebenen Befehlen und Werten definiert werden kann, außeranderen \f() Befehlen.
\f() Befehle dürfen nicht verschachtelt werden.
Beispiel: \f(100,Peter)sucht nach "Peter" in einem Block, beginnend bei Offset 0 innerhalb von 100 Bytes.
Beispiel: \p(10)\f(100,Peter)startet dieselbe Suche ab Offset 10 über 100 Bytes.
Beispiel: \p(10)\f(100,Peter)aka IsoBuster\x00sucht nach "Peter" und prüft, ob es von nullterminiertem " aka IsoBuster" gefolgt wird.
Verwenden Sie diesen Befehl nur bei Bedarf, z. B. als einzelne Regel in einer Regeldatei, um etwas sehr Spezifisches zu suchen, da dieser Befehl die Suche erheblich verlangsamen kann.
Natürlich wird die Suche nur ausgeführt, wenn ein Byte an einer festen Position zuvor übereinstimmt, was die Häufigkeit der Tests erheblich reduzieren kann.
Beispiel: \xEF\xBB\xBF\f(4,<?xml)\|.xml– es können bis zu 4 führende (leere) Zeichen vor dem <?xml-Tag in dieser UTF8-XML-Datei stehen.
\o()
ODER verschiedene Tests. Nicht nur Bytewerte (was natürlich möglich ist), sondern gesamte Sequenzen, wenn gewünscht.
Der Wert in den runden Klammern ist die Anzahl der ODER-Tests, die durchgeführt werden müssen.
\o()muss auch zwischen jedem Test der OR-Testsequenz verwendet werden und muss das OR-Testende markieren.
Beispiel: \o(2)A\o()B\o()prüft, ob das Byte bei Offset 0 entweder ASCII A oder B ist.
Der Wert in den runden Klammern ist entweder dezimal oder hexadezimal. Letzteres erfordert die Notation 0x, z. B. \p(0x03) bedeutet 3.
Beispiel: \o(2)bedeutet, dass zwei Tests durchgeführt werden müssen.
Wird der erste Test nicht erfüllt, wird der zweite Test ausgeführt. Wird der erste erfüllt, wird der zweite ignoriert. Dies kann auch mit mehr Tests gemacht werden, z. B. 4 Tests: \o(4). Werte 0 und 1 sind jedoch ungültig und führen zum Fehlschlag der gesamten Regel!
\o() akzeptiert auch einen benutzerdefinierten Ein-Zeichen-Code. Eine Art Lesezeichen. Syntax: \o(value,code)
Der Benutzer-Code ist für normale OR-Tests nicht notwendig, aber für verschachtelteOR-Tests zwingend erforderlich.
Beispiel: \o(2,a)bedeutet, dass zwei Tests ODER-verknüpft sind und der Benutzer-Code 'a' ist.
Die Syntax mit Benutzer-Code kannjederzeit verwendet werden, ist aber nur zwingend erforderlich bei verschachteltenOR-Tests.
Für verschachtelte ORs muss der Parser die Codes verwenden, sobald Sie mit der Verschachtelung beginnen.
Die \o() Syntax ist sehr strikt und muss\o() zwischenjedem Test undam Ende der Sequenz enthalten.
Bei einem Code muss dieser in den runden Klammern stehen. Ohne Code darf nichts zwischen den Klammern stehen.
Beispiel: \o(3)\x11\o()\x22\o()\0x33\o()– Das Byte kann 0x11, 0x22 oder 0x33 sein.
Mit Code: \o(3,a)\x11\o(a)\x22\o(a)\0x33\o(a)
Ein wichtigerNebeneffekt von \o() ist, dass sich der Offset nichtändert. Bei allen anderen Tests erhöht sich der Offset automatisch um 1. Nach einem \o()-Test bleibt der Offset an der gleichen Position wie vor dem Test.
Grund: Jeder Subtest in \o() kann unterschiedliche Längen haben und mit \p() und \s() beliebig innerhalb des Blocks springen. Da nicht bekannt ist, welcher Subtest erfolgreich war, muss der Offset nach dem \o() Test neu gesetzt werden.
Beispiel: \o(3,a)\x11\x12\x13\o(a)\x22\o(a)\0x33\s(5)\x33\o(a)– je nach Subtest verschiebt sich der Offset unterschiedlich; nach \o() ist er wieder an der ursprünglichen Position.
Beispiel: \o(3)\x11\o()\x22\o()\0x33\o()\s(1)0x44\|.blah – Byte 0 kann 0x11, 0x22 oder 0x33 sein; \s(1) erhöht den Offset um 1, damit Byte 1 gegen 0x44 geprüft werden kann.
Beispiel für verschachteltes \o(): \o(3)\x11\o()\x22\o(2,a)\x23\o(a)\x24\o(a)\o()\0x33\o()
Der Code hilft dem Parser, die Tests korrekt zuzuordnen.
Jeder Subtest ist ein eigenständiger Test und kann alle oben genannten Befehle und Werte verwenden. Verwenden Sie die Codesunbedingt bei verschachtelten \o(), z. B. \o(2,c) ...
Nur ein paar reale Beispiele:
LZANIM\|.lza
\xFF\xD8\xFF\o(2)\xE?\o()\xFE\o()\|.jpg
GIF\o(2)8\o()\#\x??\o()\|.gif
\#ID3\|.mp3
MM\x00\x2A\|.kdc
\x4F\x67\x67\x53\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\|.ogg
SFW/|.sfw
\x60\xEA\o(2)\p(8)\x10\x00\x02\o()\#\x??\o()\|.arj
gzip-\>\=1\s(-1)\<\=9.\>\=1\s(-1)\<\=9.\>\=1\s(-1)\<\=9\|.gz
\xEF\xBB\xBF\f(4,<?xml)\|.xml
MSWIM\x00\x00\|.wim
\x01\p(0x13)\x3E\x40\p(7)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.btd
\x00\p(0x80)DICM\f(200,1.2.840.10008.1.3.10)\p(1)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.dicomdir
\x00\p(0x80)DICM\p(1)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.dcm
%vsm%\s(3)\x00P\x00r\x00o\x00d\x00u\x00c\x00e\x00d\p(0x29)S\x00o\x00f\x00t\x00w\x00a\x00r\x00e\|.vp3
#PES0001\|.pes
\x??Embird Outline Format v\|.eof
\x??\x00\x00\x00\x0A\x00\x00\x0020\|.jef