Personalizzare regole firma dei file
Questo è principalmente per ingegneri ed esperti di recupero dati, sebbene qualsiasi appassionato possa facilmente comprenderlo e iniziare a usarlo!
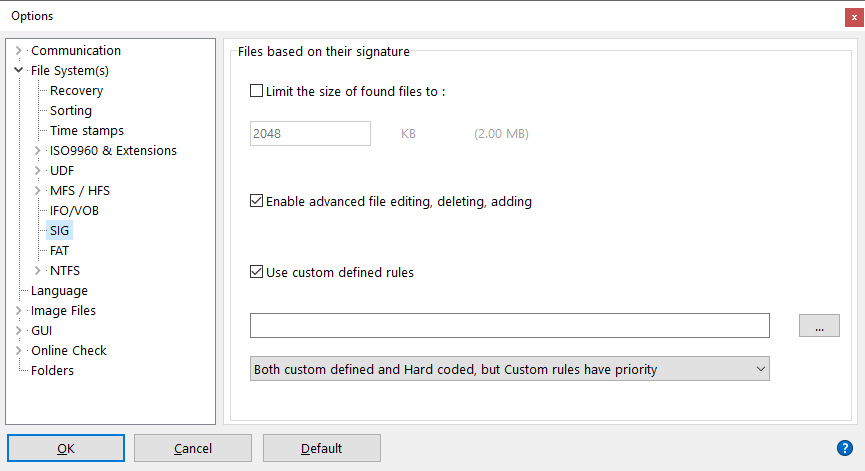
IsoBuster è in grado di caricare e utilizzare regole definite dall'utente per trovare file basati sulla firma definita.
I file *.rules sono file di testo puro che contengono una regola per riga e possono essere memorizzati ovunque tu possa caricarli. Oppure puoi semplicemente metterli nella cartella /plugins/.
Puoi selezionare il file *.rules che IsoBuster deve usare tramite le opzioni. Vedi lo screenshot sopra.
Quando la casella "Usa regole definite dall'utente" è selezionata, IsoBuster carica e utilizza il file *.rules definito in ogni operazione "Trova file e cartelle mancanti" per popolare la lista "File trovati in base alla loro firma".
Ci sono tre possibili scenari per l'uso delle regole personalizzate, selezionabili tramite il menu a discesa in fondo alla finestra (vedi screenshot sopra):
- Solo le regole definite dall'utente.
- Entrambe le regole hard-coded (integrate nel programma) e le regole personalizzate, ma prima vengono controllate le regole personalizzate; se non c'è corrispondenza, vengono usate le regole hard-coded.
- Entrambe le regole hard-coded (integrate nel programma) e le regole personalizzate, ma prima vengono usate le regole hard-coded; se non c'è corrispondenza, vengono provate le regole personalizzate.
I file *.rules contengono una regola per riga.
Poiché l'analisi di un file di testo non è veloce come il codice incorporato, la sintassi di ogni riga è molto rigorosa! Nel momento in cui la sintassi non rispetta le regole illustrate di seguito, il test fallirà o potrebbe generare un falso positivo.
È consigliabile mettere solo regole valide in un file *.rules e tenere commenti ecc. fuori dal file, eventualmente in un secondo file, per migliorare la velocità.
Per testare una regola, può essere utile caricare il file di tipo target in IsoBuster (come presunto file immagine) e eseguire "Trova file e cartelle mancanti". Se la firma definita viene trovata all'indirizzo (LBA) 0, allora la regola funziona.
Ogni regola viene testata su ogni blocco letto.
Quindi, per ogni blocco, l'intera lista di regole viene verificata prima di passare al blocco successivo, ecc.
Se il supporto è ottico (CD, DVD, BD), la regola viene attivata ogni 2048 byte. Se è un Hard Disk o una chiavetta USB, la regola viene testata su ogni blocco da 512 byte o ogni blocco da 4096 byte su unità 4kn.
L'offset iniziale è 0 in ogni blocco, a meno che IsoBuster non rilevi una struttura di file system che precede un possibile file all'interno dello stesso blocco, ad esempio file incorporati in descrittori NTFS o FAT.
I blocchi con determinate strutture di file system che non contengono dati di file vengono saltati e non saranno ulteriormente testati.
Ogni blocco viene testato rispetto a ogni regola nel file delle regole fino a quando una riga non corrisponde ai dati, dopodiché si passa al blocco successivo.
Ogni regola lavora per byte, parte dall'indice 0 del blocco presentato e procede al byte successivo una volta che un byte è stato testato rispetto al valore nella regola.
Ogni comando nella riga è preceduto da un backslash ed è di dimensione di un solo carattere. Quindi backslash e comando combinati sono sempre 2 caratteri.
I valori e i comandi in una regola / riga:
\%
Un commento [Funzionalità disponibile da IsoBuster 4.7]
Tutto ciò che segue questo comando in una riga viene ignorato. Tutto ciò che precede viene elaborato normalmente. Non aggiungere spazi iniziali, consumerebbero solo tempo durante la scansione.
\i()
Assegna un ID univoco a una riga [Funzionalità disponibile da IsoBuster 4.7]
Questo consente ad altri comandi, che sono ID-aware, di applicare la loro logica a questa riga o al file trovato grazie a questa riga.
Un ID nonpuò essere 0 (zero) e deveessere minore o uguale a 65535 (0xFFFF)
\e()
Termina un file precedentemente trovato (che è ancora aperto) [Funzionalità disponibile da IsoBuster 4.7]
Questo comando è ID-aware (fornisci l'ID tra parentesi)
Quando un file è stato trovato tramite la sua firma, ma non è stata ancora rilevata una nuova firma e quindi la dimensione del file sta ancora crescendo, questo comando può essere usato per terminare il file.
Idealmente emesso con un ID corrispondente a un'altra riga (e quindi al tipo di file)
Se non viene fornito un valore/ID tra le parentesi, questo comando termina qualsiasifile trovato che sta ancora crescendo.
In quest'ultimo scenario viene usato per rilevare firme che terminano qualsiasi file, ma non fanno parte dei file stessi.
\c()
Concatenare a un file precedentemente trovato (che è ancora aperto) [Funzionalità disponibile da IsoBuster 4.7]
Questo comando è ID-aware (fornisci l'ID tra parentesi)
Quando la firma in questa riga corrisponde ai dati, invece di "terminare" il file precedentemente trovato (che è ancora aperto e in crescita) e iniziarne uno nuovo, il file precedentemente trovato continuerà semplicemente a crescere.
I dati vengono quindi concatenati al file precedentemente trovato. Questo comando è utile per gestire firme ricorrenti nei file.
Ad esempio, la riga \i(1)\c(1)\x00\x00\x01\xba\|.VOBgarantisce che non vengano trovati x file VOB da 2048 byte, ma invece un solo file con x * 2048 byte.
\#
Determinare la dimensione di un file è un'approssimazione. Generalmente la dimensione di un file è determinata dalla posizione di inizio del file successivo o da una struttura del file system trovata.
Se IsoBuster incontra una struttura del file system e quindi assume che il file precedentemente trovato termini qui, passerà un parametro Booleano al test/blocco successivo che indica questo.
Questo parametro Booleano può essere usato soloper attivare quando il valore Booleano è vero. Il comando \#fa esattamente questo.
Ad esempio, supponiamo che tu sappia che un file inizia con i valori di due byte \x1F\x8B
Tuttavia, questa firma è così generica che verrà trovata molte volte all'interno di file esistenti, causando falsi positivi e tagliando i file precedentemente trovati.
Una tale regola è meglio lasciarla fuori, ma puoi comunque consentirla, solo quando IsoBuster segnala che il file precedentemente trovato è terminato comunque.
In tal caso puoi usare la regola \#\x1F\x8B\|.gz
Fai in modo che \# sia il primo comando in una riga se decidi di usarlo. Questo migliorerà notevolmente la velocità.
\|
Per motivi di velocità, ogni riga inizia con il test e termina con il comando \|
\| è seguito dall'estensione, ad esempio: \#\x1F\x8B\|.gz
e opzionalmente l'estensione può essere seguita da | dimensione del file in byte. Questo può essere usato quando si conoscela dimensione reale del file. Ad esempio: \#\x01\x02\|.gz|1000
\x
Ogni test per byte nella regola può essere specificato in due modi: come valore esadecimale \x00o come valore ASCII (vedi oltre).
La sintassi è molto rigorosa. Ci devono sempre essere due caratteri in notazione esadecimale e il range è (ovviamente) \x00 - \xFF
È anche possibile testare solo un nibble. In tal caso usare ?per il nibble che non vuoi testare. Esempio: \0x?3corrisponderà ai valori 0xF3, 0xE3, 0xD3,..., 0x03.
\x??significa che non vuoi testare questo byte, può avere qualsiasi valore, è come saltare un byte. Esempio: \0x00\0x01\x??\x01\x00: i byte 0,1,3 e 4 devono corrispondere, byte 2 può avere qualsiasi valore.
PS. Non usare il wildcard nibble ?nei valori byte che devono essere più piccoli o più grandi (o uguali). Quindi non in combinazione con \> o \< o \>= o \<=, poiché potrebbe avere effetti indefiniti e quindi inattendibili.
Caratteri ASCII
Tutti i caratteri leggibili tra i valori byte 32 e 126 possono essere usati per il test.
Ad esempio: GIF\|.gif è un test valido ed è essenzialmente lo stesso di: \x47IF\|.gifo G\x49F\|.gifecc.
\ è anche un carattere valido, ma poiché il backslash viene usato per i valori e comandi speciali, è necessario raddoppiare \quando lo si usa come valore di test: \\
\v()
Confronta il valore del byte all'offset corrente con un valore di byte all'offset definito con \v()
Il valore tra le parentesi tonde è decimale o esadecimale. Quest'ultimo richiede la notazione 0x, per esempio \v(0x0F) verifica se il byte corrente corrisponde al byte all'offset 15. Questo comando può essere combinato con \> \< \<= e \>=
Per esempio, questo esempio: \v(5)\x10verifica se il primo byte all'offset 0 corrisponde al byte all'offset 5 e, se sì, verifica se il secondo byte all'offset 1 corrisponde a 0x10
\p()
Cambia la Posizione / Offset assoluta nel blocco di dati prima di eseguire il test successivo
Per esempio: \p(3)\x01\x02significa che l'offset cambia da 0 a 3, e quindi il byte 3 nel blocco dati deve corrispondere a 0x01 e il byte 4 deve corrispondere a 0x02
Puoi saltare a qualsiasi posizione nel blocco di dati, ma devi rimanere entro i confini del blocco, altrimenti il test fallirà.
Puoi saltare avanti e indietro se ha senso per qualsiasi motivo. Per esempio, per motivi di velocità, testare un byte molto preciso più avanti nel blocco e solo se corrisponde tornare all'inizio del blocco e testare altri byte.
Per esempio: \p(100)PP\p(0)\f(100,OK)verifica l'esistenza di "P" all'offset 100 e "P" all'offset 101 e, se ciò è vero, continua a cercare nei primi 100 byte la stringa "OK"
Il valore tra le parentesi tonde è decimale o esadecimale. Quest'ultimo richiede la notazione 0x, per esempio \p(0xFF) salta all'offset 255 etc.
\s()
Cambia la posizione saltando sun certo numero di byte dalla posizione corrente.
Per esempio, l'esempio usato in precedenza: \0x00\0x01\x??\x01\x00 può anche essere scritto come: \0x00\0x01\s(1)\x01\x00
Il valore tra le parentesi tonde è decimale o esadecimale. Quest'ultimo richiede la notazione 0x, per esempio \s(0x10) salta 16 byte.
È anche possibile saltare un numero negativo di byte (solo usando notazione decimale).
Per esempio \s(-1) salta indietro di un byte. Questo può essere utile per testare un singolo byte contro diversi parametri. Per esempio, se un byte è compreso tra due valori.
Eg. \>\x10\s(-1)\<\=\x20verifica se un byte è maggiore di 16 e minore o uguale a 32.
\=
= è implicito e ridondante.
Ogni test su un byte assume che il byte nel blocco di dati corrisponda al byte nella regola.
Tuttavia, se messo dopo \> o \< per esempio \>\= o \<\= si traduce in >= o <=
\>
Metti \> prima di un valore di byte, ad esempio \>\x33 significa che il byte nel blocco dati deve essere maggiore di 0x33 (invece di essere uguale a 0x33)
Se seguito immediatamente da \=, si traduce in >=, per esempio \>\=\x33significa che il byte nel blocco dati deve essere maggiore o uguale a 0x33
\<
Metti \< prima di un valore di byte, ad esempio \<\x50significa che il byte nel blocco dati deve essere minore di 0x50 (invece di essere uguale a 0x50)
Se seguito immediatamente da \=, si traduce in <=
\f()
Trova una condizione a partire dall'offset iniziale, su un intervallo definito. Se la condizione è soddisfatta, l'offset successivo si trova subito dopo la condizione cercata.
La sintassi deveessere \f(range,condizione)
Mantieni l'intervallo all'interno del blocco. La condizione può essere praticamente qualsiasi cosa definibile con tutti i comandi e valori descritti qui, eccettoaltri comandi \f().
I comandi \f() non possono essere nidificati.
Per esempio \f(100,Peter)cercherà "Peter" all'interno di un blocco, a partire dall'offset 0 e entro l'intervallo di 100 byte.
Per esempio \p(10)\f(100,Peter) inizierà la stessa ricerca dall'offset 10 su un intervallo di 100 byte
Per esempio \p(10)\f(100,Peter) aka IsoBuster\x00 cercherà "Peter" e, se trovato, verificherà se è seguito da " aka IsoBuster" terminato da null
Usa questo comando solo quando necessario. Per esempio come regola singola in un file di regole, per cercare qualcosa di molto specifico, perché questo comando può rallentare considerevolmente la ricerca.
Naturalmente, se inizi la regola con un byte in una posizione fissa che deve corrispondere a un certo valore prima, la ricerca verrà eseguita solo se almeno quel valore fisso corrisponde. Ciò può ridurre significativamente il numero di ricerche.
In questo esempio: \xEF\xBB\xBF\f(4,<?xml)\|.xmlpossono esserci fino a 4 caratteri finali (vuoti) prima del tag <?xml in questo file xml UTF8.
\o()
OR tra test diversi. Non solo valori di byte (che ovviamente è possibile) ma intere sequenze se desiderato.
Il valore tra le parentesi tonde è il numero di test OR che devono essere eseguiti.
\o()deve essere usato anche tra ogni test possibile della sequenza OR e deve anche seguire il test OR.
Per esempio, \o(2)A\o()B\o()verifica se il byte all'offset 0 è ASCII A o B
Il valore tra le parentesi tonde è decimale o esadecimale. Quest'ultimo richiede la notazione 0x, per esempio \p(0x03) significa 3
Per esempio \o(2)significa che ci sono due test da eseguire.
Se il primo test non corrisponde, deve essere eseguito il secondo test. Se il primo corrisponde, il secondo viene ignorato. Questo può essere fatto anche con più test, ad esempio 4 test: \o(4). I valori 0 e 1 sono valori impossibili e faranno fallire l'intera regola!
\o() accetta anche un codice utente a singolo carattere. Una sorta di segnalibro. La sintassi allora è: \o(valore,codice)
Il codice utente non è necessario per i normali test OR, ma se vuoi nidificaretest OR dentro altri test OR, allora è assolutamente necessario!
Per esempio \o(2,a)significa che ci sono due test OR e il codice utente è 'a'
La sintassi con codice utente puòessere usata in qualsiasi momento ma è necessaria solo quando si vogliono eseguire test OR nidificati.
Perché il parser delle regole capisca OR nidificati, deviusare codici non appena inizi a nidificare test OR.
La sintassi \o() è molto rigorosa e devecontenere \o() traogni test ealla fine della sequenza.
In caso di codice, devecontenere il codice tra le parentesi tonde. In caso di assenza di codice, non deve esserci nullatra le parentesi tonde.
Per esempio: \o(3)\x11\o()\x22\o()\0x33\o()significa che il byte all'offset dato può essere 0x11, 0x22 o 0x33
In caso sia stato usato un codice, la sintassi deveessere: \o(3,a)\x11\o(a)\x22\o(a)\0x33\o(a)per lo stesso test.
Un effetto importantedel test \o() è che l'offset non cambiadopo il test. Per tutti gli altri test l'offset aumenta automaticamente di 1. Quindi in una sequenza di 3 byte (es. \x00\x01\x02 ) il primo byte viene controllato, poi il secondo (offset +1), poi il terzo (offset +1 di nuovo) e così via.
Dopo un test \o(), tuttavia, l'offset nel blocco di dati rimane ancoraallo stesso punto in cui era prima del test \o(). Questo perché ogni sotto-test nell'OR può avere lunghezza variabile e ogni sotto-test può portarti ovunque nel blocco usando \p() e \s(). Poiché non puoi sapere quale sotto-test ha avuto successo e dove si trova il puntatore/offset, prima che il prossimo test venga eseguito devi riposizionare l'offset.
Per esempio: \o(3,a)\x11\x12\x13\o(a)\x22\o(a)\0x33\s(5)\x33\o(a)Se il primo sotto-test ha avuto successo l'offset si sarebbe spostato di 3 byte. Se il secondo test ha avuto successo l'offset si sarebbe spostato solo di 2 byte. Se entrambi i test 1 e 2 falliscono ma il terzo ha successo, il puntatore si sarebbe spostato di 6 byte. Quindi ... poiché è sconosciuto, dopo il test \o() il puntatore torna dove era prima dell'inizio del test.
In questo esempio: \o(3)\x11\o()\x22\o()\0x33\o()\s(1)0x44\|.blah il byte 0 può essere 0x11, 0x22 o 0x33, e se quella condizione è soddisfatta, \s(1) aumenta l'offset di uno affinché il byte 1 possa essere testato contro il valore 0x44
Un esempio di test \o() nidificato è: \o(3)\x11\o()\x22\o(2,a)\x23\o(a)\x24\o(a)\o()\0x33\o()
L'uso del codice aiuta il parser a capire quale parte appartiene a quale test.
Ogni sotto-test è un test a sé che può usare qualsiasi comando o valore sopra citato. Assicurati solo di usare i codici menzionatiseinizi a nidificare \o(), es. \o(2,c) ...
Alcuni esempi reali:
LZANIM\|.lza
\xFF\xD8\xFF\o(2)\xE?\o()\xFE\o()\|.jpg
GIF\o(2)8\o()\#\x??\o()\|.gif
\#ID3\|.mp3
MM\x00\x2A\|.kdc
\x4F\x67\x67\x53\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\|.ogg
SFW/|.sfw
\x60\xEA\o(2)\p(8)\x10\x00\x02\o()\#\x??\o()\|.arj
gzip-\>\=1\s(-1)\<\=9.\>\=1\s(-1)\<\=9.\>\=1\s(-1)\<\=9\|.gz
\xEF\xBB\xBF\f(4,<?xml)\|.xml
MSWIM\x00\x00\|.wim
\x01\p(0x13)\x3E\x40\p(7)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.btd
\x00\p(0x80)DICM\f(200,1.2.840.10008.1.3.10)\p(1)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.dicomdir
\x00\p(0x80)DICM\p(1)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.dcm
%vsm%\s(3)\x00P\x00r\x00o\x00d\x00u\x00c\x00e\x00d\p(0x29)S\x00o\x00f\x00t\x00w\x00a\x00r\x00e\|.vp3
#PES0001\|.pes
\x??Embird Outline Format v\|.eof
\x??\x00\x00\x00\x0A\x00\x00\x0020\|.jef
Maggiori informazioni su Github