Reglas de Archivos de Firma Personalizados
¡ Esto es principalmente para ingenieros y expertos en la recuperación de datos aunque también cualquier entusiasta puede intentarlo y comenzar a usarlo de forma experimentalt !
IsoBuster es capaz de cargar y usar reglas definidas por el usuario para encontrar archivos basados en una firma definida.
Los archivos *.rules son archivos puramente de texto que contienen una regla por cada línea y pueden ser almacenados en cualquier sitio desde el cual usted puede cargarlos. O simplemente colocarlo en la carpeta de /plugins
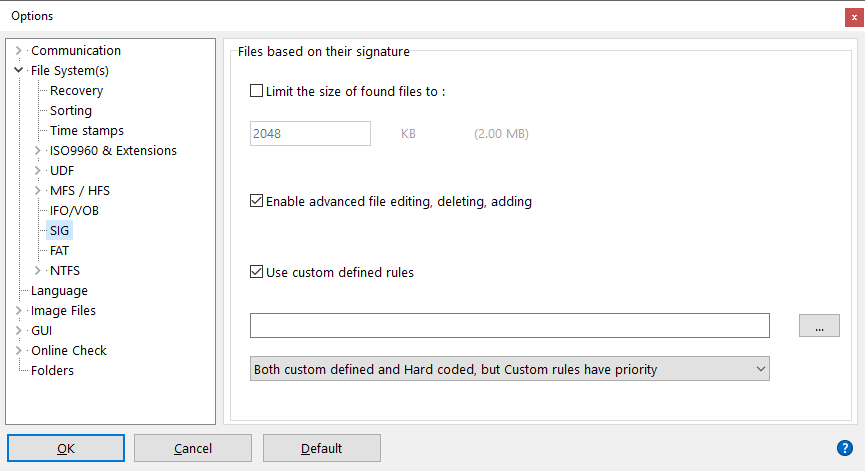
Usted puede seleccionar el archivo *.rules que necesita IsoBuster usar por medio de las opciones. Vea la captura de pantalla de arriba.
Cuando el casillero "Usar reglas definidas personalizadas" se marca, IsoBuster carga y usa el archivo *.rules definido en cada operación de "Encontrar archivos y carpetas que faltan" para ayudar a poblar la Lista de "Archivos encontrados basados en sus firmas" sistema de archivos.
Existen tres posibles escenarios para usar las reglas personalizadas. Pueden ser seleccionados por medio de la ventana emergente en la parte inferior de la ventana (Vea la captura de pantalla de arriba) :
- Solamente las reglas personalizadas definidas.
- Tanto las reglas de codificación fija (programa anidado) y las reglas personalizadas, pero primero las reglas personalizadas y marcadas, y si no hay coincidencia, entonces se usan las reglas de codificación fijas.
- Tanto las reglas de codificación fija (programa anidado) y las reglas personalizadas, pero primero las reglas de codificación fija, y si no hay coincidencia, entonces se intenta usan las reglas personalizadas.
Los archivos *.rules contienen una regla por línea.
¡ Debido a que el cambio a la siguiente línea de un archivo de texto no es tan rápido como un código anidado, la sintaxis de cada línea es muy estricta ! En el momento que la sintaxis no siga las reglas indicadas debajo, la prueba puede fallar o generar un falso positivo.
Es mejor solamente poner reglas válidas en un archivo *.rules y mantener los comentarios etc. fuera del archivo posiblemente en un segundo archivo, ya que así se mejora la velocidad.
Para probar una regla, le puede ayudar a cargar el tipo de archivo de destino en IsoBuster (como si fuera un archivo de imagen presumido) y ejecutar "Encontrar archivos y carpetas que Faltan". Si la firma definida se encuentra en la dirección (LBA) 0, entonces la regla funciona.
Cada regla es probada en cada bloque que se lee.
Así para cada bloque de la lista completa de todas las reglas se comprobará antes de pasar al siguierte bloque etc.
i el medio es óptico (CD, DVD, BD) la regla se dispara cada 2048 bytes. Si se trata de un Disco Duro o USB stick, la regla se prueba cada bloque de 512 bytes o cada 4096 bytes en unidades de 4kn.
El comienzo del offset es 0 en cada bloque, a menos que IsoBuster detecte una estructura de sistema de archivo que preceda a un posible archivo dentro del mismo bloque. P.e. archivos que hayan sido anidados en descriptores de archivos NTFS o FAT.
Los bloques con ciertas estructuras de archivo de sistema que no contengan datos son saltados y no volverán a ser probados posteriormente.
Cada bloque es probado contra cada regla en el archivo de reglas hasta que una línea coincida con el dato, después de lo cual se prueba el próximo bloque.
Cada regla trabaja por byte, se inicia en index 0 del bloque actual y continúa con el siguiente byte una vez que un byte ha sido probado contra el valor en la regla.
De cada comando en la línea se escapa con una diagonal inversa y solamente tiene el tamaño de un caracter. Así que la diagonal inversa y el comando combinado son siempre 2 caracteres.
Los valores y comandos en una regla / línea:
\%
Un comentario [Functionalidad disponible desde IsoBuster 4.7]
Cualquier cosa que siga a este comando en una línea es ignorado. Cualquie cosa que le preceda se procesa de forma normal. Así que al no incluir espacios al inicio, se evitará el consumo de tiempo de proceso durante la exploración.
\i()
Asignar un ID único a una línea [Functionalidad disponible desde IsoBuster 4.7]
Esto permite que otros comandos, que consideren el ID, aplicar su magia a esta línea en particular o más bien al archivo que ha sido encontrado debido a esta línea.
Un ID no puede ser 0 (cero) y debe ser menor (o igual) que 65535 (0xFFFF)
\e()
Finalizar un archivo previamente encontrado (que está todavía abierto) [Functionalidad disponible desde IsoBuster 4.7]
Este comando depende del ID (proorcione el ID entre corchetes)
Cuando el archivo fue encontrado mediante esta firma, pero todavía no se ha detectado la firma, y por tanto el tamaño del archivo todavía está creciendo, este comando puede usarse para finalizar el archivo.
Idealmente diseñado para usar con un ID que corresponde con otra línea (y más bien tipo de archivo)
Si no se proporciona un valor de ID entre corchetes, este comando 'finaliza' cualquier archivo encontrado que está creciendo.
Como último escenario, se usa para detectar firmas que terminen cualquier archivo, pero que no son parte del mismo archivo.
\c()
Encadenar a un archivo previamente encontrado (que todavía se encuentra abierto) [Functionalidad disponible desde IsoBuster 4.7]
Este comando depende del ID (proporcione el ID entre corchetes)
Cuando la firma en esta línea coincide con los datos, en vez del 'final' del archivo encontrado previamente (que está abierto y creciendo), y se inicia uno nuevo, el archivo previamente encontrado simplemente crecerá.
Los datos entonces se concadanarán al archivo previamente encontrado. Puede parecer un comando sin uso, pero es particularmente útil para el tratamiento de archivos de firma recurrentes.
En lugar de encontrar x archivos cada vez que la firma es detectada, le ayuda a encontrar un archivo que contenga x firmas.
Por ejemplo, la línea \i(1)\c(1)\x00\x00\x01\xba\|.VOB le asegura que no se encuentren x archivos VOB con 2048 bytes, sino un archivo con x * 2048 bytes
\#
Encontrar el tamaño de un archivo es un trabajo de apreciación. Generalmente el tamaño de un archivo está determinado por la localización de inicio del siguiente archivo o por una estructura de de archivo de sistema que se encuentre.
Si IsoBuster entra en una estructura de archivo de sistema y presume que el archivo previamente encontrado termina ahí, pasará el parámetro booleano al próximo bloque de texto indicando esta situación.
Este parámetro booleano solamente puede ser usado cuando el valor booleano es válido. El command \# hace eso exactamente.
Por ejemplo, asumiendo que usted conoce que un archivo comienza con un valor de dos bytes \x1F\x8B
Sin embargo, la firma es tan genérica que puede encontrarse muchas veces dentro de archivos existentes, ocasionando muchos falsos positivos y cortando los archivos previamente encontrados en en tamaños cortos.
Tal regla es mejor dejarla fuera, pero usted todavía puede permitirla, pero solamente cuando IsoBuster señale que el archivo previamente encontrado terminó de todas formas.
En este caso usted puede usar la regla \#\x1F\x8B\|.gz
Haga que \# seacel primer comando en una línea si decide usarlo. Con ello se mejorará grandemente la velocidad.
\|
Por razones de rapidez, cada línea comienza con el test y termina con el comando \|
El comando \| está seguido por la extensión, por ejemplo: \#\x1F\x8B\|.gz
Y opcionalmente la extensión puede ser seguida por | tamaño del archivo en bytes. Esto puede ser usado para cuando usted conoce cuál es la longitud real del archivo. Por ejemplo: \#\x01\x02\|.gz|1000
\x
Cada prueba de byte en la regla puede ser especificado de dos formas diferentes. Con un calor hexadecimal \x00 o con un valor ASCII (ver más adelante).
La sintaxis es muy estricta. Siempre deben existir dos caracteres en una notación hexadecimal y el rango es (obviamente) \x00 - \xFF
También es posible probar solamente un trocito. En este caso use ? para el trocito que usted no desea probar. P.e. \0x?3 coincidirá con los valores de byte 0xF3, 0xE3, 0xD3, ..., 0x23, 0x13, 0x03.
Y en el caso de \x?? significaría que usted no desea probar este byte por completo, puede tener cualquier valor, y es igual que saltar un byte. P.e. en la secuencia: \0x00\0x01\x??\x01\x00 los bytes 0,1,3 y 4 deben coincidir, y el 2 puede tener cualquier valor.
PS. No use el wildcard ? en valores de byte que necesiten ser menores o mayores (y o iguales) que. Así que no lo combine con \> o \< o \>\= o \<\= porque tendrá efecto indefinido y por tanto no confiable.
ASCII character
Todos los caracteres legibles entre los valores de byte 32 y 126 pueden ser usados para las pruebas.
Por ejemplo: GIF\|.gif es una prueba válida, y es esencialmente lo mismo que: \x47IF\|.gif o G\x49F\|.gif etc.
\ es también un carácter válido, pero debido a que la barra invertida es usada para escapar de lo valores especiales y comandos, usted necesita hacer doble \ cuando lo usa como un valor de prueba: E.j. \\
\v()
Comparar el valor de byte en el offset actual con un valor de byte definido con \v()
El valor entre los dos paréntesis es decimal o hexadecimal. En el caso de ser hexadecimal requiere la notación 0x , por ejemplo en elcaso de la prueba \v(0x0F) prueba si el valor de byte probado coincide con el valor de byte en el offset 15. Este comando puede ser combinado con \> \< \<= y \>=
Por ejemplo: \v(5)\x10 prueba si el primer byte en el offset 0 coincide con el byte en el offset 5 y también, prueba el segundo byte en el offset 1 coincide con 0x10
\p()
Cambiar la Posición / Offset absolutos en el bloque de datos antes de hacer la próxima prueba
Por ejemplo: \p(3)\x01\x02 significa que el offset es cambiado de 0 a 3, y por tanto el byte 3 en el bloque de datos debe coincidir con 0x01 y el byte 4 debe coincidir con 0x02
Usted puede saltar a cualquier posición en el bloque de datos pero necesita permanecer dentro de los límites del bloque o la prueba fallará.
You can jump back and forth if that makes sense for whatever reason. For instance, for speed reasons, test a very strict and certain byte value Posteriormente en el bloque y solamente si ha coincidido, saltar atrás al comienzo del bloque y probar otros bytes.
Por ejemplo: \p(100)PP\p(0)\f(100,OK) prueba la existencia de "P" en el offset 100, y "P" en el offset 101, y si es verdadero continúa para probar los primeros 100 bytes para el texto "OK"
El valor entre los paréntesis puede ser decimal o hexadecimal. En este último caso requiere la notación 0x, por ejemplo \p(0xFF) salta al offset 255 etc.
\s()
Cambiar la posición saltando una cantidad de bytes desde la posición actual.
Por ejemplo, en el caso del ejemplo anteriormente usado: \0x00\0x01\x??\x01\x00 puede también ser escrito como: \0x00\0x01\s(1)\x01\x00
El valor entre los paréntesis puede ser decimal o hexadecimal. En este último caso requiere la notación 0x, por ejemplo \s(0x10) salta 16 bytes.
También es posible saltar una cantiddad negattiva de bytes (solamente usando una notación decimal).
Por ejemplo \s(-1) salta un byte hacia atrás. Esto puede ser muy útil para probar un solo valor de byte contra diferentes parámetros. P.e. si un valor de byte está entre dos valores.
P.e. \>\x10\s(-1)\<\=\x20 prueba si el valor de un byte es más alto que 16 y menor o igual que 32.
\=
= es implicado y redundante.
Cada prueba de byte asume que el byte en el bloque de datos coincide en la regla
Sin embargo, si se pone detrás\de \> o \< por ejemplo \>\= o \<\= se traduce como >= o <=
\>
Poner \> antes de un valor de byte, p.e. \>\x33 significa que el byte en el bloque de datos debe ser mayor de 0x33 (en vez de ser igual a 0x33)
Cuando está seguido inmediatamente por \=, se traduce como >= p.e. \>\=\x33 lo cual significa que el byte en el bloque de tatos debe ser mayor o igual a 0x33
\<
Poner \< antes de un valor de byte, p.e. \<\x50 significa que el byte en el bloque de datos debe ser menor de 0x50 (en vez de ser igual a 0x50)
Cuando está inmediatamente seguido por \=, se traduce como <=
\f()
Encontrar una condición comenzando desde el offset de inicio, sobre un rango definido. Si la condición es encontrada, el próximo offset es situado justo después de la condición para la cual se ha realizado la búsqueda.
La sintaxis debe de ser \f(rango,condición)
Mantenga el rango dentro del bloque. La condición debe ser con mucha probabilidad algo que pueda ser definido por todos los los comandos y valores definidos aquí.
Por ejemplo \f(100,Peter) buscará "Peter" dentro de un bloque, comenzando desde el offset 0 y dentro del rango de 100 bytes.
Por ejemplo \p(10)\f(100,Peter) iniciará la misma búsqueda desde el offset 10 sobre un rango de 100 bytes
Por ejemplo \p(10)\f(100,Peter) aka IsoBuster\x00 buscará "Peter" y si lo encuentra comprobará si está seguido de null terminado por "aka IsoBuster"
Use este comando solamente cuando lo necesite hacerlo. Por ejemplo como una regla sencilla en un archivo de reglas, para buscar algo muy específico, porque este comando puede reducir considerablemente la búsqueda.
Por supuesto, si usted comienza la regla con un byte en una posición fija necesitando la coincidencia con cierto valor primeramente, la búsqueda solamente será realizada si al menos el valor de esa localización fija coincide. Esto puede reducir la búsqueda solicitada considerablemente
En este ejemplo: \xEF\xBB\xBF\f(4,<?xml)\|.xml pueden haber hasta 4 caracteres de inicio (blanco) antes de la etiquete de <?xml en este archivo UTF8 xml.
\o()
Diferentes tests de OR. No solamente los valores de byte (que son naturalmente posibles) sino también secuencias enteras si usted lo desea.
El valor entre los paréntesis es la cantidas de pruebas de OR que usted necesita que se realicen.
\() también necesita ser usado entre cada posible test de la secuencia de pruebas OR y también necesita estar al final de la prueba OR.
P.e. el test \(2)A\o()B\o() si el byte en el offset 0 es ASCII A o B
El valor entre los paréntesis puede ser decimal o hexadecimal. En el segundo caso se requiere la notació 0x , por ejemplo \p(0x03) significa 3
Por ejemplo \o(2) significa que hay dos tests que necesitan ser realizados.
Si el primer test no coincide, el segundo test necesita ser realizado. Si el primer test encontró coincidencia, el segundo test es ignorado. Esto puede hacerse con más tests, p.e. 4 tests: \o(4). ¡Los valores 0 y 1 son valores imposibles, y por tanto fallará la regla completa !
\o() también acepta un código definido por el usuario con un simple carácter. Como una forma de marcador si usted lo desea. La sintaxis es: \o(valor,código)
¡ El código definido por el usuario no es necesario para los tests normales OR pero si usted desea hacer un test de anidado OR dentro de tests OR, entonces es absolutamente necesario !
Por ejemplo \o(2,a) significa que hay dos tests que necesitan ser tratados como OR y el código definido por el usuario es 'a'
La sintaxis de un código definido por usuario puede ser usado siempre pero es absolutamente necesario cuando usted desea ejecutar tests anidados OR.
Para que la regla de parser tenga sentido de ORs usted necesita usar códigos en el momento que inicia el anidado de los tests OR.
La sintaxis de \o() es muy estricta y debe contener \o() entre cada test y al final de la secuencia.
En el caso de un código, estet debe contener el código entre paréntesis. En el caso de no existir código, es necesario que nada exista entre los paréntesis.
Por ejemplo: \o(3)\x11\o()\x22\o()\0x33\o() Esto significa que el valor del byte en el offset dado puede ser 0x11 o 0x22 o 0x33
En el caso de que un código ha sido usado, la sintaxis debe ser: \o(3,a)\x11\o(a)\x22\o(a)\0x33\o(a) para el mismo test.
Un importante efecto colateral del test \o() es que el no cambia después de la prueba. Para cualquier otro test el offset automáticamente se incrementa con 1. Así que en una secuencia de test de 3 bytes (p.e. \x00\x01\x02 ) el primer byte se comprobará, a continuación el segundo byte (así que el offset se mueve uno hacia arriba), a continuación el tercer byte (y nuevamente offset se mueve uno hacia arriba) y así sucesivamente.
Sin embargo, después de un test \o(), el offset dentro del bloque de datos está todavía en el mismo punto donde estaba antes del test \o(). La razón para esto es porque cada sub-test en el test OR puedda ser de una longitud variable, y cada sub-test pueda llevarle a usted a cualquier sitio dentro del bloque de datos usando \p() y \s(). Ya que usted no puede conocer cuál sub-test fue el coincidente y dónde terminó el pointer/offset, antes de que el próximo test sea ejecutado, usted necesita posicionar el offset nuevamente.
Por ejemplo: \o(3,a)\x11\x12\x13\o(a)\x22\o(a)\0x33\s(5)\x33\o(a) Si el primer sub-test acierta, el offset debe haberse movido hacia arriba 3 bytes. Sin embargo, si el segundo test acierta, el offset debe haberse movido hacia arriba solamente 2 byte. Si tanto el test 1 como el test 2 fallan, pero el tercero acierta el apuntador debe moverse hacia arriba 6 bytes. Así que ... aunque esto es desconocido, después del test \o() el apuntador ha regresado al punto en que estaba antes de iniciar la prueba.
En este ejemplo: \o(3)\x11\o()\x22\o()\0x33\o()\s(1)0x44\|.blah el byte 0 puede ser 0x11 o 0x22 o 0x33, y si esta condición se cumple, \s(1) incrementa el offset con uno para que el byte 1 pueda ser probado contra el valor 0x44
Un ejemplo para un test \o() anidado es: \o(3)\x11\o()\x22\o(2,a)\x23\o(a)\x24\o(a)\o()\0x33\o()
El uso del código ayuda al parser a imaginar cuál parte pertenece a cada test.
Cada sub test es un test en sí mismo que puede usar cualquiera de los comandos y valores usados anteriormente. Solamente asegúrese de usar los códigos mencionados si usted inicia una prueba \o() con anidado p.e. \o(2,c) ...
Solamente unos pocos ejemplos de la vida real:
LZANIM\|.lza
\xFF\xD8\xFF\o(2)\xE?\o()\xFE\o()\|.jpg
GIF\o(2)8\o()\#\x??\o()\|.gif
\#ID3\|.mp3
MM\x00\x2A\|.kdc
\x4F\x67\x67\x53\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\|.ogg
SFW/|.sfw
\x60\xEA\o(2)\p(8)\x10\x00\x02\o()\#\x??\o()\|.arj
gzip-\>\=1\s(-1)\<\=9.\>\=1\s(-1)\<\=9.\>\=1\s(-1)\<\=9\|.gz
\xEF\xBB\xBF\f(4,<?xml)\|.xml