Règles personnalisées de signature de fichiers
Ceci est principalement destiné aux ingénieurs et aux experts en récupération de données, bien que tout passionné puisse facilement le prendre en main et commencer à l’utiliser !
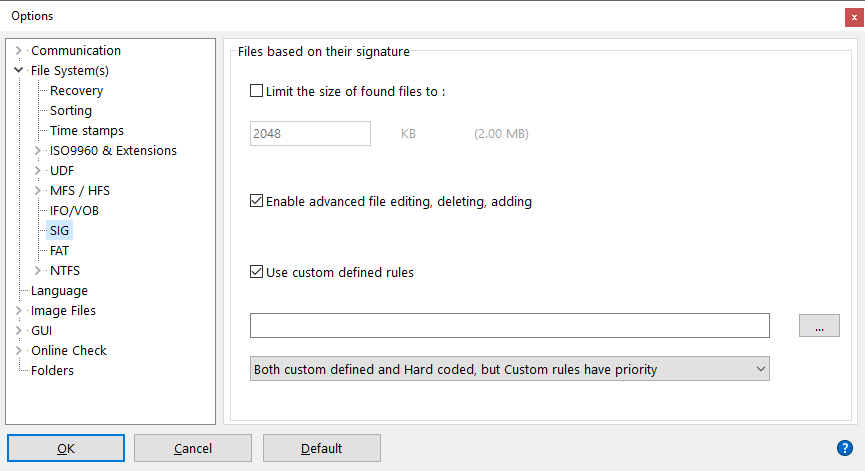
IsoBuster est capable de charger et d’utiliser des règles définies par l’utilisateur pour trouver des fichiers en fonction de la signature définie.
Les fichiers *.rules sont des fichiers texte purs contenant une règle par ligne et peuvent être stockés n’importe où d’où vous pouvez les charger. Ou simplement les placer dans le dossier /plugins/.
Vous pouvez sélectionner le fichier *.rules qu’IsoBuster doit utiliser via les options. Voir la capture d’écran ci-dessus.
Lorsque la case "Utiliser des règles définies par l’utilisateur" est cochée, IsoBuster charge et utilise le fichier *.rules défini à chaque "Rechercher des fichiers et dossiers manquants" pour aider à remplir la liste "Fichiers trouvés en fonction de leur signature" du système de fichiers.
Il existe trois scénarios possibles pour utiliser les règles personnalisées. Ils peuvent être sélectionnés via le menu déroulant en bas de la fenêtre (voir capture d’écran ci-dessus) :
- Uniquement les règles définies par l’utilisateur.
- À la fois les règles codées en dur (intégrées au programme) et les règles personnalisées, mais les règles personnalisées sont vérifiées en premier, et si aucune correspondance, les règles codées en dur sont utilisées.
- À la fois les règles codées en dur (intégrées au programme) et les règles personnalisées, mais les règles codées en dur sont vérifiées en premier, et si aucune correspondance, les règles personnalisées sont essayées.
Les fichiers *.rules contiennent une règle par ligne.
Comme l’analyse d’un fichier texte n’est pas aussi rapide que le code intégré, la syntaxe de chaque ligne est très stricte ! Dès que la syntaxe ne respecte pas les règles ci-dessous, le test échouera ou pourra déclencher un faux positif.
Il est préférable de ne mettre que des règles valides dans un fichier *.rules et de laisser les commentaires, etc., dans un fichier séparé, car cela améliorera la vitesse.
Pour tester une règle, il peut être utile de charger le fichier cible dans IsoBuster (comme un fichier image présumé) et d’exécuter "Rechercher des fichiers et dossiers manquants". Si la signature définie est trouvée à l’adresse (LBA) 0, alors la règle fonctionne.
Chaque règle est testée sur chaque bloc lu.
Ainsi, pour chaque bloc, l’ensemble de toutes les règles sera vérifié avant de passer au bloc suivant, etc.
Si le support est optique (CD, DVD, BD), la règle sera déclenchée tous les 2048 octets. Si c’est un disque dur ou une clé USB, la règle sera testée sur chaque bloc de 512 octets ou chaque bloc de 4096 octets sur les disques 4kn.
Le décalage de départ est 0 dans chaque bloc, sauf si IsoBuster détecte une structure de système de fichiers qui précède un fichier possible dans le même bloc, par exemple des fichiers intégrés dans des descripteurs de fichiers NTFS ou FAT.
Les blocs contenant certaines structures de système de fichiers qui ne contiennent pas de données de fichiers sont ignorés et ne seront pas testés davantage.
Chaque bloc est testé contre chaque règle du fichier de règles jusqu’à ce qu’une ligne corresponde aux données, après quoi le bloc suivant est testé.
Chaque règle fonctionne par octet, commence à l’indice 0 du bloc présenté et passe à l’octet suivant une fois qu’un octet a été testé par rapport à la valeur de la règle.
Chaque commande de la ligne est échappée avec un antislash et ne fait qu’un caractère. Ainsi, antislash et commande combinés font toujours 2 caractères.
Les valeurs et commandes dans une règle / ligne :
\%
Un commentaire [Fonctionnalité disponible depuis IsoBuster 4.7]
Tout ce qui suit cette commande sur une ligne est ignoré. Tout ce qui précède est traité normalement. Ne mettez donc pas d’espaces en tête, ils ne feront que consommer du temps de traitement pendant l’analyse.
\i()
Attribuer un ID unique à une ligne [Fonctionnalité disponible depuis IsoBuster 4.7]
Cela permet à d’autres commandes, sensibles aux ID, d’appliquer leur magie à cette ligne particulière ou plutôt au fichier trouvé grâce à cette ligne.
Un ID ne peut pas être 0 et doit être inférieur ou égal à 65535 (0xFFFF)
\e()
Terminer un fichier précédemment trouvé (toujours ouvert) [Fonctionnalité disponible depuis IsoBuster 4.7]
Cette commande est sensible aux ID (fournir l’ID entre parenthèses)
Lorsqu’un fichier a été trouvé via sa signature, mais qu’aucune nouvelle signature n’a encore été détectée et donc que la taille du fichier continue de croître, cette commande peut être utilisée pour terminer le fichier.
Idéalement, elle est utilisée avec un ID correspondant à une autre ligne (et donc à un type de fichier)
Si aucune valeur/ID n’est fournie entre parenthèses, cette commande « termine » tout fichier trouvé qui est encore en croissance.
Dans ce dernier scénario, elle sert à détecter des signatures qui terminent tout fichier, mais ne font pas partie des fichiers eux-mêmes.
\c()
Concaténer à un fichier précédemment trouvé (toujours ouvert) [Fonctionnalité disponible depuis IsoBuster 4.7]
Cette commande est sensible aux ID (fournir l’ID entre parenthèses)
Lorsque la signature de cette ligne correspond aux données, au lieu de « terminer » le fichier précédemment trouvé (toujours ouvert et en croissance) et de démarrer un nouveau, le fichier précédemment trouvé continue simplement à croître.
Les données sont donc concaténées au fichier précédemment trouvé. Cette commande peut sembler inutile, mais elle est particulièrement utile pour gérer des signatures récurrentes dans les fichiers.
Au lieu de trouver x fichiers chaque fois que la signature est détectée, cela permet de trouver un seul fichier contenant les x signatures.
Par exemple, la ligne \i(1)\c(1)\x00\x00\x01\xba\|.VOB garantit que l’on ne trouve pas x fichiers VOB de 2048 octets, mais un seul fichier contenant x * 2048 octets.
\#
Trouver la taille d’un fichier est approximatif. Généralement, la taille d’un fichier est déterminée par l’emplacement du fichier suivant ou par une structure de système de fichiers trouvée.
Si IsoBuster rencontre une structure de système de fichiers et suppose donc que le fichier précédemment trouvé se termine ici, il passe un paramètre booléen au test/bloc suivant indiquant cela.
Ce paramètre booléen peut être utilisé uniquement lorsque la valeur booléenne est vraie. La commande \# fait exactement cela.
Par exemple, supposons que vous savez qu’un fichier commence par les deux octets \x1F\x8B
Cependant, cette signature est si générique qu’elle sera trouvée de nombreuses fois à l’intérieur des fichiers existants, provoquant de nombreux faux positifs et tronquant la taille des fichiers précédemment trouvés.
Une telle règle est préférable de la laisser de côté, mais vous pourriez encore l’autoriser, uniquement lorsque IsoBuster signale que le fichier précédemment trouvé est déjà terminé.
Dans ce cas, vous pouvez utiliser la règle \#\x1F\x8B\|.gz
Faites de \# la première commande sur une ligne si vous décidez de l’utiliser. Cela améliorera grandement la vitesse.
\|
Pour des raisons de vitesse, chaque ligne commence par le test et se termine par la commande \|
\| est suivi de l’extension, par exemple : \#\x1F\x8B\|.gz
et éventuellement, l’extension peut être suivie de | la taille du fichier en octets. Cela peut être utilisé lorsque vous savez combien de octets contient réellement le fichier. Par exemple : \#\x01\x02\|.gz|1000
\x
Chaque test d’octet dans la règle peut être spécifié de deux manières. Comme valeur hexadécimale \x00 ou comme valeur ASCII (voir ci-dessous).
La syntaxe est très stricte. Il doit toujours y avoir deux caractères en notation hexadécimale et la plage est (évidemment) \x00 - \xFF
Il est également possible de tester seulement une demi-octet. Dans ce cas, utilisez ? pour la demi-octet que vous ne voulez pas tester. Par exemple \0x?3 correspond aux valeurs d’octet 0xF3, 0xE3, 0xD3, ..., 0x23, 0x13, 0x03.
\x?? signifie que vous ne voulez pas tester cet octet du tout, il peut avoir n’importe quelle valeur, c’est équivalent à ignorer un octet. Par exemple dans la séquence : \0x00\0x01\x??\x01\x00, les octets 0,1,3 et 4 doivent correspondre, l’octet 2 peut avoir n’importe quelle valeur.
PS. N’utilisez pas le joker de demi-octet ? dans des valeurs d’octet qui doivent être inférieures ou supérieures (et/ou égales) à quelque chose. Donc pas en combinaison avec \> ou \< ou \>\= ou \<\= car cela produira des effets indéfinis et donc peu fiable.
Caractère ASCII
Tous les caractères lisibles entre la valeur d’octet 32 et 126 peuvent être utilisés pour tester.
Par exemple : GIF\|.gif est un test valide, et est essentiellement équivalent à : \x47IF\|.gif ou G\x49F\|.gif, etc.
\ est également un caractère valide mais comme l’antislash est utilisé pour échapper les valeurs et commandes spéciales, vous devezdoubler le \ lorsque vous l’utilisez comme valeur de test : \\
\v()
Comparez la valeur de l’octet à l’offset actuel avec la valeur de l’octet à l’offset défini avec \v()
La valeur entre parenthèses est soit décimale, soit hexadécimale. Pour l’hexadécimal, utilisez la notation 0x, par exemple \v(0x0F) teste si l’octet testé correspond à l’octet à l’offset 15. Cette commande peut être combinée avec \> \< \<= et \>=
Par exemple : \v(5)\x10teste si le premier octet à l’offset 0 correspond à l’octet à l’offset 5 et, si oui, teste si le deuxième octet à l’offset 1 correspond à 0x10
\p()
Change la position / l’offset absolu dans le bloc de données avant d’effectuer le test suivant
Par exemple : \p(3)\x01\x02signifie que l’offset passe de 0 à 3 ; l’octet 3 dans le bloc de données doit correspondre à 0x01 et l’octet 4 à 0x02
Vous pouvez sauter à n’importe quelle position dans le bloc, mais vous devez rester dans les limites du bloc ou le test échouera
Vous pouvez revenir en arrière ou avancer si nécessaire. Par exemple, pour des raisons de vitesse, testez un octet très précis plus loin dans le bloc et, si la condition est remplie, revenez au début du bloc pour tester d’autres octets
Par exemple : \p(100)PP\p(0)\f(100,OK)teste l’existence de "P" à l’offset 100 et "P" à l’offset 101, et si c’est vrai, continue à chercher dans les 100 premiers octets le texte "OK"
La valeur entre parenthèses peut être décimale ou hexadécimale. Exemple : \p(0xFF) saute à l’offset 255
\s()
Change la position en sautant un certain nombre d’octets depuis la position actuelle
Exemple : la séquence précédente \x00\x01\x??\x01\x00 pourrait s’écrire : \x00\x01\s(1)\x01\x00
La valeur entre parenthèses peut être décimale ou hexadécimale. Exemple : \s(0x10) saute 16 octets
Il est aussi possible de sauter un nombre négatif d’octets (seulement en décimal)
Exemple : \s(-1) recule d’un octet. Utile pour tester un octet par rapport à plusieurs conditions. Exemple : \>\x10\s(-1)\<=\x20 teste si un octet est supérieur à 16 et inférieur ou égal à 32
\=
= est implicite et redondant
Chaque test d’octet suppose que l’octet du bloc correspond à celui de la règle
Si placé après \> ou \<, traduit respectivement >= ou <=
\>
Placez \> avant un octet, ex. \>\x33 signifie que l’octet doit être supérieur à 0x33
Si suivi immédiatement par \=, traduit >=. Exemple : \>\=\x33 signifie que l’octet doit être supérieur ou égal à 0x33
\<
Placez \< avant un octet, ex. \<\x50 signifie que l’octet doit être inférieur à 0x50
Si suivi immédiatement par \=, traduit <=
\f()
Recherche une condition à partir de l’offset de départ sur une plage définie. Si la condition est remplie, l’offset suivant se situe juste après la condition
Syntaxe : \f(plage, condition)
Gardez la plage dans le bloc. La condition peut utiliser n’importe quelle commande ou valeur décrite ici, saufd’autres \f(). Les \f() ne peuvent pas être imbriquées
Exemple : \f(100,Peter) cherche "Peter" dans un bloc à partir de l’offset 0 sur 100 octets
Exemple : \p(10)\f(100,Peter) commence la recherche à l’offset 10 sur 100 octets
Exemple : \p(10)\f(100,Peter) aka IsoBuster\x00 cherche "Peter" et, si trouvé, vérifie qu’il est suivi de " aka IsoBuster" terminé par un nul
Utilisez \f() seulement si nécessaire ; cela peut ralentir considérablement la recherche. Commencer par un octet fixe peut réduire les appels inutiles
Exemple : \xEF\xBB\xBF\f(4,<?xml)\|.xml permet jusqu’à 4 caractères blancs avant la balise <?xml dans un fichier XML UTF-8
\o()
Test OR (OU) entre différents tests, pas seulement des octets mais des séquences entières
La valeur entre parenthèses indique le nombre de tests OR à effectuer
\o() doit être utilisé entre chaque test et à la fin de la séquence
Exemple : \o(2)A\o()B\o() teste si l’octet à l’offset 0 est soit ASCII A soit B
La valeur peut être décimale ou hexadécimale. Exemple : \p(0x03) = 3
Exemple : \o(2) signifie 2 tests. Si le premier échoue, le second est exécuté. Les valeurs 0 et 1 sont invalides
\o() accepte aussi un code utilisateur à un caractère, syntaxe : \o(valeur, code). Obligatoire seulement pour des OR imbriqués
Exemple OR imbriqué : \o(3,a)\x11\o(a)\x22\o(a)\x33\o(a)
Comportement de l’offset : après un test \o(), l’offset reste inchangé car chaque sous-test peut avancer différemment
Exemple : \o(3)\x11\o()\x22\o()\x33\s(1)0x44\|.blah – l’octet 0 peut être 0x11, 0x22 ou 0x33, puis \s(1) incrémente l’offset pour tester 0x44
Juste quelques exemples concrets :
LZANIM\|.lza
\xFF\xD8\xFF\o(2)\xE?\o()\xFE\o()\|.jpg
GIF\o(2)8\o()#\x??\o()\|.gif
#ID3\|.mp3
MM\x00\x2A\|.kdc
\x4F\x67\x67\x53\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\|.ogg
SFW/|.sfw
\x60\xEA\o(2)\p(8)\x10\x00\x02\o()#\x??\o()\|.arj
gzip-\>=1\s(-1)\<=9.\>=1\s(-1)\<=9.\>=1\s(-1)\<=9\|.gz
\xEF\xBB\xBF\f(4,<?xml)\|.xml
MSWIM\x00\x00\|.wim
\x01\p(0x13)\x3E\x40\p(7)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.btd
\x00\p(0x80)DICM\f(200,1.2.840.10008.1.3.10)\p(1)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.dicomdir
\x00\p(0x80)DICM\p(1)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.dcm
%vsm%\s(3)\x00P\x00r\x00o\x00d\x00u\x00c\x00e\x00d\p(0x29)S\x00o\x00f\x00t\x00w\x00a\x00r\x00e\|.vp3
#PES0001\|.pes
\x??Embird Outline Format v\|.eof
\x??\x00\x00\x00\x0A\x00\x00\x0020\|.jef
Plus d’infos sur Github